
")

In the field of machine learning, artificial neural networks have stimulated new developments and impressive results in terms of achieved quality. At the same time, there is a controversy regarding the energy used for training and operating such networks. Hence, many research groups strive to overcome this energy bottleneck.
Neuromorphic computing in its original sense was meant to replicate the dynamics of biological neuronal networks with integrated circuits as to achieve similar computing efficiencies as seen in nature. Today, the term ‘neuromorphic computing’ is used to generically label a wide variety of techniques from algorithm to hardware that focus on better energy efficiency in the domain of neural networks.
In this domain, the chair develops methods to apply such techniques for the execution of ANNs on embedded devices. Such techniques include cost models on the different design entry levels which allow us to quantify for example the trade-off between quality of results and consumed energy.
Quantitative modeling for Algorithm-Hardware Co-Design
In well-established domains like specifying a signal processing data path or the instruction set architecture, methods have been refined to breakdown system level requirements to the level of individual processing modules. As a result, there is a wealth of cost modelling techniques in order to scout for more efficient system realizations to execute neural networks – nowadays including aspects such as neuromorphic algorithms or novel electronic devices. The properties of data driven applications have thereby created additional challenges when compared to classic requirements.
Modern applications introduced large datasets and neural networks, which led to further challenges of high-quality labeling, uncertainty of result, processing bottlenecks, and redundancies in the network. While there exist common techniques on the algorithmic side, their implications on the lower design levels remain to be explored. To bring this field forward, we have proposed a tool flow that works with abstractions from the lower to higher design levels as done in the classic case.
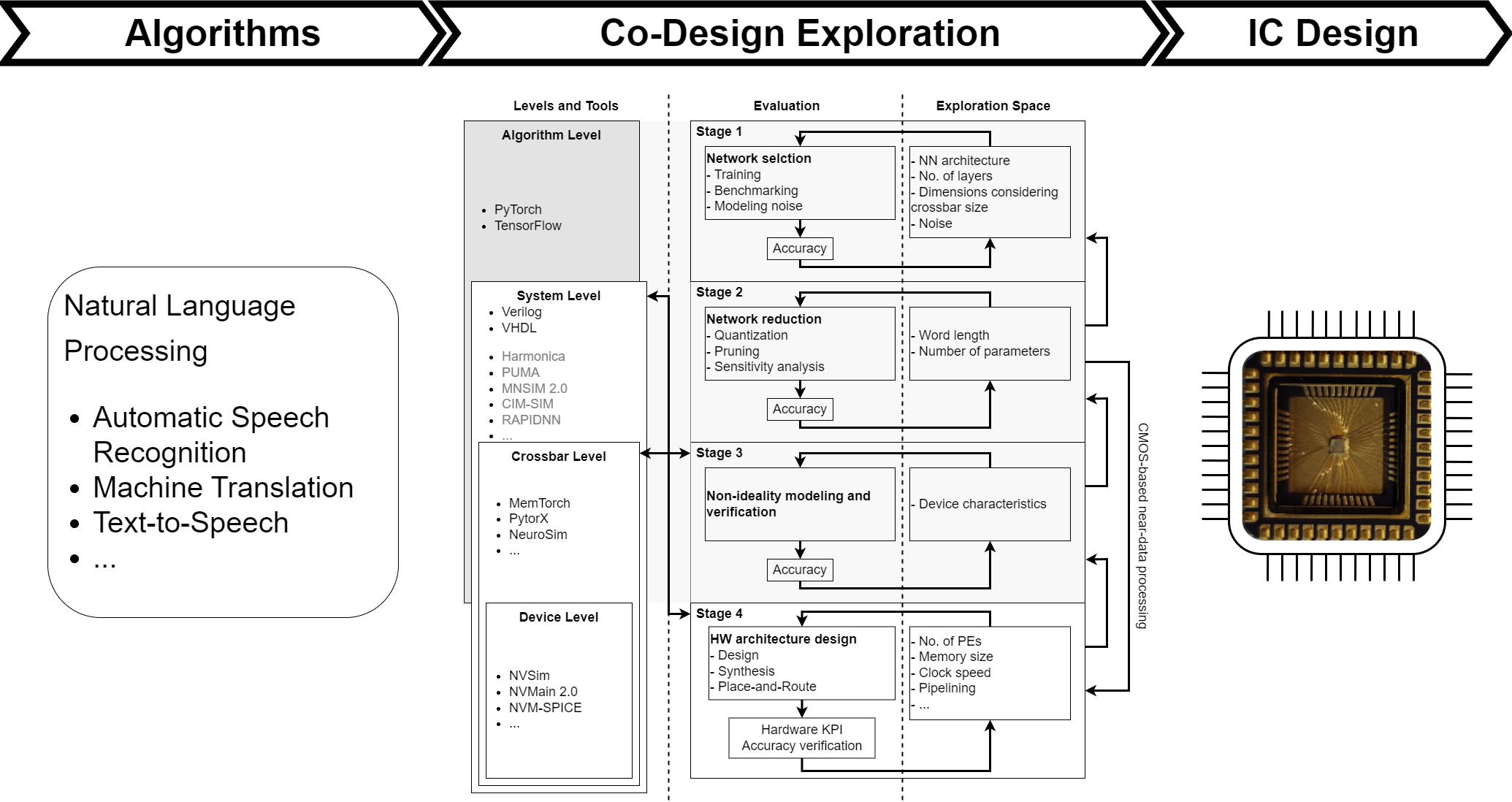
Algorithm-Hardware Co-Design Flow
[M. Wabnitz et al., “Toolflow for the algorithm-hardware co-design of memristive ANN accelerators,” Memories - Materials, Devices, Circuits and Systems, 2023, doi: 10.1016/j.memori.2023.100066]
Additional features are propagated upward and downward to represent the introduced and tolerated uncertainty on the different levels. In the end, this extends the classic approximations introduced by limited word lengths to other deterministic or random errors in the computations.
Lightweight CNNs for Edge-AI Acceleration
Our research focuses on the design of lightweight Convolutional Neural Networks (CNNs) for deployment on edge platforms with stringent constraints on power, memory, and computation. We explore algorithmic techniques such as Depthwise Separable Convolution (DSC), quantization, and pruning to significantly reduce model complexity while maintaining high accuracy. Building on these foundations, we propose a series of dedicated DSC accelerators, from a unified engine to a dual-engine architecture, culminating in a Group-wise Uniform Pruning Accelerator (GUPA). These designs eliminate redundant data movement and integrate quantization and pruning at the hardware level to achieve optimal performance.
[Y. Chen et al., “An energy-efficient and area-efficient depthwise separable convolution accelerator with minimal on-chip memory access,” IFIP/IEEE International Conference on Very Large Scale Integration (VLSI-SoC), 2023, doi: 10.1109/vlsi-soc57769.2023.10321918]
[Y. Chen et al., “A unified and energy-efficient depthwise separable convolution accelerator,” Springer Nature Computer Science Book, 2024, doi: 10.1007/978-3-031-70947-0_7]
[Y. Chen et al., “EDEA: Efficient dual-engine accelerator for depthwise separable convolution with direct data transfer,” IEEE International System-on-Chip Conference (SOCC), 2024, doi: 10.1109/SOCC62300.2024.10737823]
[Y. Chen et al., “GUPA: Group-wise uniform pruning accelerator for depthwise separable convolution,” IEEE Symposium in Low-Power and High-Speed Chips (COOL CHIPS), 2025, doi: 10.1109/COOLCHIPS65488.2025.11018601]
Approximate Computations
In the wealth of approximate computing techniques (e.g., Gansen22), pushing quantization to the very limit can be considered an initial step. Firstly, deriving the minimal necessary number of bits for a fixed-point representation has been an integral part in the design of digital signal processing data-paths.
Secondly, such approximation is deterministic which enables the use of efficient verification and validation techniques. Thirdly, the number of bits used has a major impact on memory requirements and power consumed in data transfers, which dominate the overall energy budget in data driven use cases. Last but not least, a lower number of effective bits required in the computation additionally favors analog design solutions considering energy expenditure.
Research on materials, devices, and module level requires extensive exploration of a large design space. For that purpose, small, established datasets like MNIST and CIFAR-10 are used. To foster research in these fields, we provide examples of trained neuronal networks publicly [github, Stadtmann20], that can actually operate with binary values (+1 and -1) while providing results close to floating point computations. This repository includes all parameters, python code as well as details to (re)train the networks.
| network model | dataset | accuracy [float] [binary] |
| LeNet5 VGGNet7 |
mnist cifar10 |
99.50 99.16 94.05 89.85 |
Artificial neural network architecture
[github, T. Stadtmann et al., “From quantitative analysis to synthesis of efficient binary neural networks,” ICMLA, 2020, doi: 10.1109/ICMLA51294.2020.00024, pdf]
Low data-rate streaming architectures
As AI technology becomes increasingly advanced in their capabilities, the continuous monitoring of data requires specialized components for efficient analysis. This enables the same functional capabilities as state-of-the-art AI models even in resource-constrained devices, such as wearable devices. At the institute, we use the vehicle of ECG classification to demonstrate that through a structured algorithm-hardware co-design methodology, classical DSP components as well as biologically-inspired hardware components achieve ultra-low power consumption in a continuous operation. The design and optimization of such components under consideration of multiple objectives (e.g. quality of service, energy per solution) is a hot research topic, as specifications become increasingly tighter due to higher demands for device complexity and model functionality.
[J. Loh et al., “Lossless Sparse Temporal Coding for SNN-based Classification of Time-Continuous Signals,” DATE, 2023, doi: 10.23919/DATE56975.2023.10137112 , pdf]
[J. Loh et al., “Dataflow Optimizations in a Sub-uW Data-Driven TCN Accelerator for Continuous ECG Monitoring,” NorCAS, 2022, doi: 10.1109/NorCAS57515.2022.9934591 , pdf]
[J. Loh et al., “Low-Cost DNN Hardware Accelerator for Wearable, High-Quality Cardiac Arrythmia Detection,” ASAP, 2020, doi: 10.1109/ASAP49362.2020.00042 , pdf]
Natural Language Processing (NLP)
NLP is a broad field of research spanning tasks of speech recognition, speech translation, speech synthesis, and more. Power, latency, and privacy concerns started a trend of executing these tasks on embedded hardware instead of using large compute centers. At our chair, we analyze state-of-the-art techniques and optimize them through algorithm-hardware co-design. For these optimized networks, we build highly efficient hardware accelerators exploring promising computation paradigms like approximate and in-memory computing.